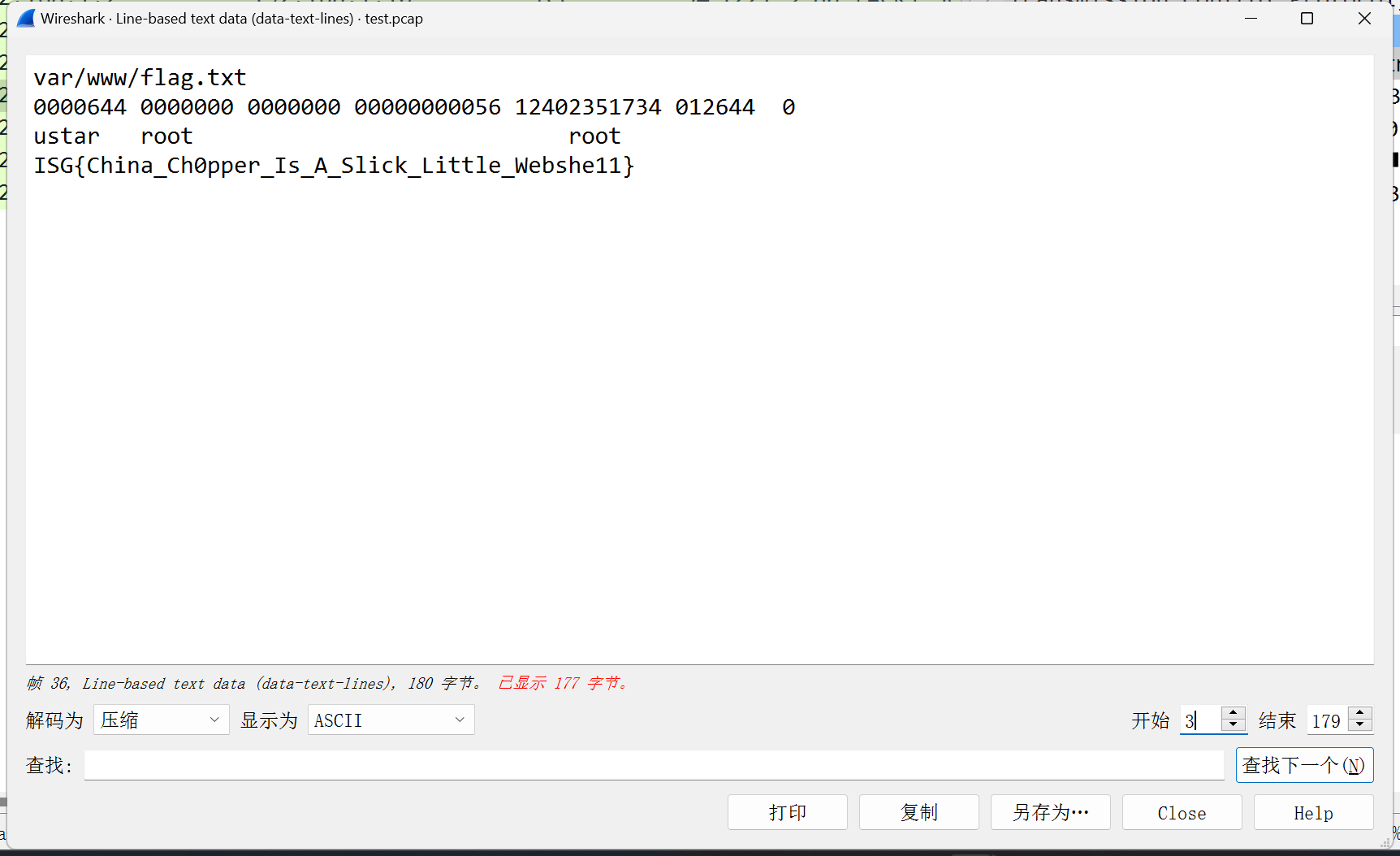
flag 为明文
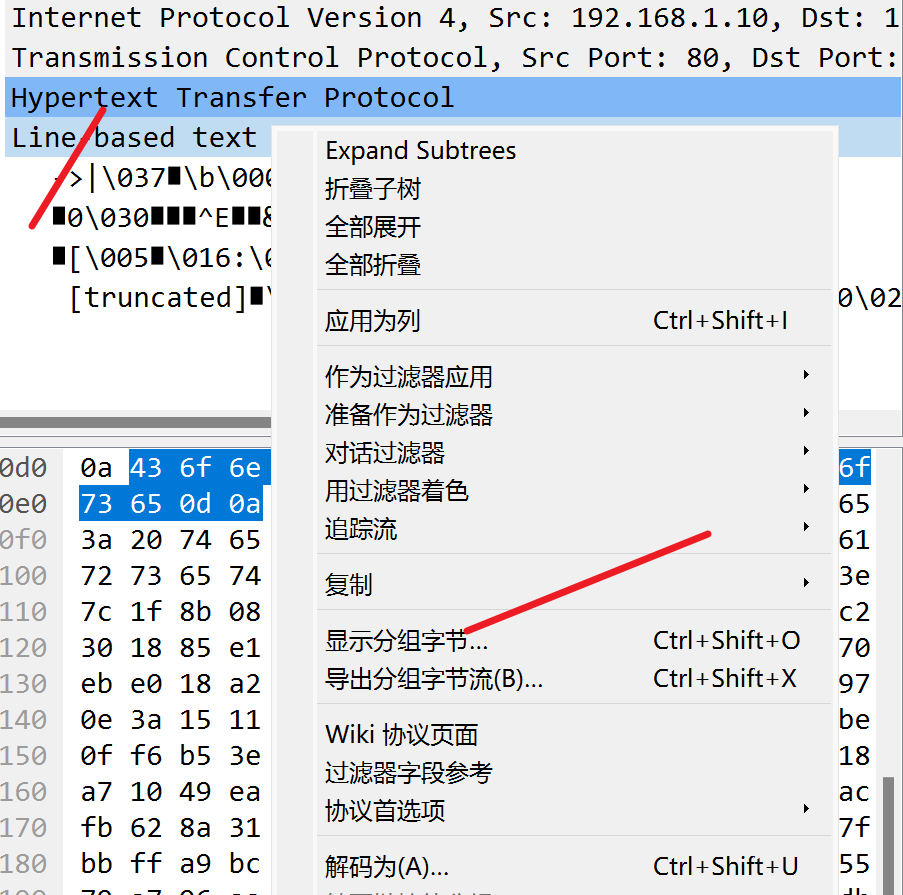
直接搜索,WireShark设置如下

关于分组字节流,请看
- “分组字节流” 是数据包的原始二进制表示,以十六进制显示。
- “分组列表” 是捕获到的数据包的可视化列表,显示数据包的摘要信息。
- “分组详情” 提供选定数据包的深层解析,包括每个协议的详细信息。
flag为编码
flag的十六进制编码:666c6167
方法
通过脚本进行扫描,然后从扫描排查的输出进行判断flag的格式
脚本:
1 | # encoding:utf-8 |
三种硬编码区分
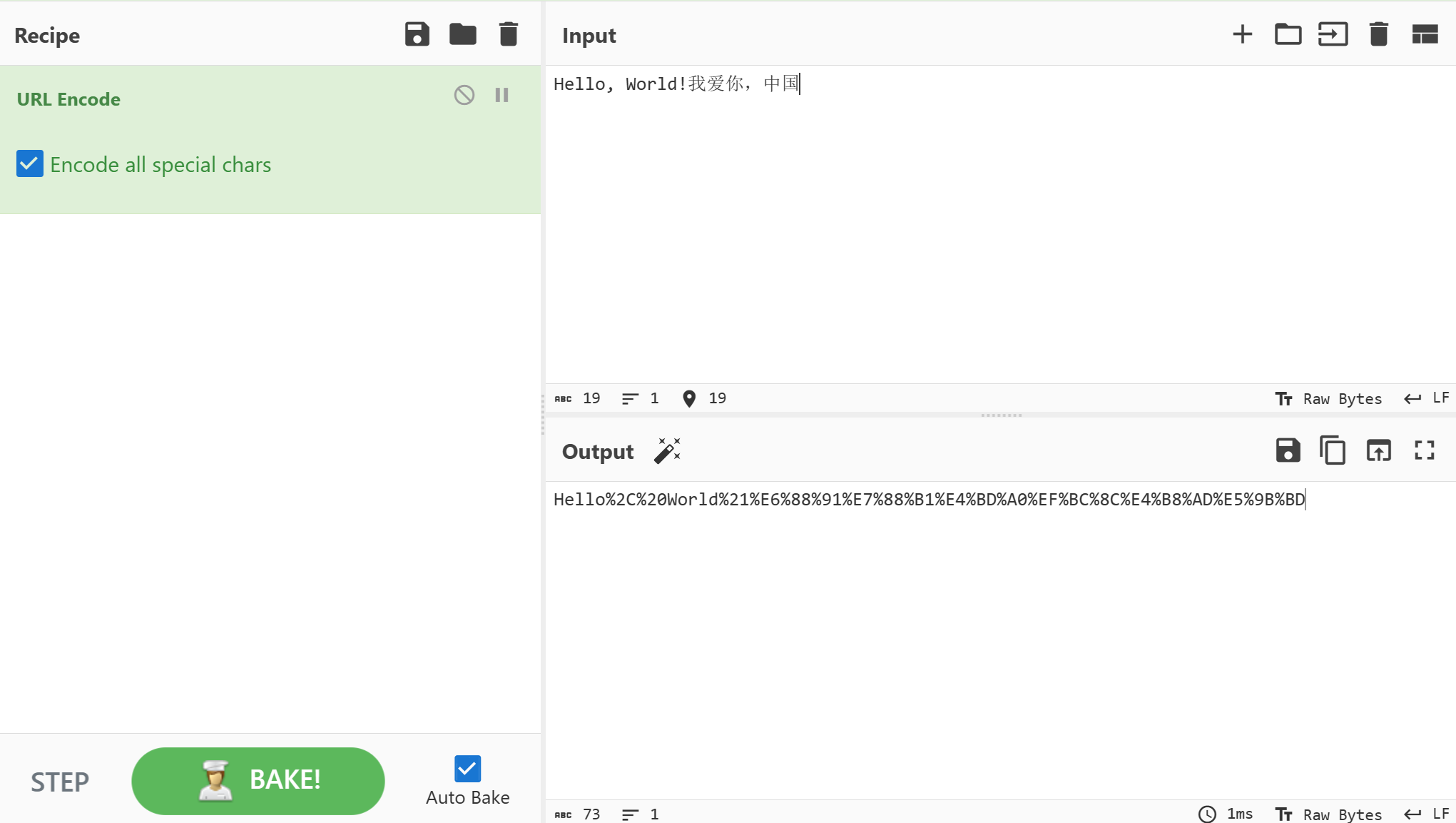
- URL编码(URL Encoding): URL编码也称为百分号编码(Percent Encoding),是一种用于在URL中表示特殊字符的编码方式。它将URL中的非字母数字字符转换为特殊格式:%xx,其中xx是字符的十六进制ASCII码表示。这样做是为了避免特殊字符与URL的语法冲突。
例如,空格字符(ASCII码为32)在URL编码后将变成”%20”。其他特殊字符也有相应的编码形式。
- 字符串:Hello, World!
- URL编码后:Hello%2C%20World%21
厨子处理
- Unicode编码: Unicode编码是一种字符编码标准,用于表示世界上所有字符的唯一代码点。它为每个字符分配了一个唯一的整数值,称为Unicode码点。不同的字符集如UTF-8、UTF-16和UTF-32等以不同方式表示Unicode字符。
- 字符:爱 (中文“爱”字)
- Unicode码点:U+7231
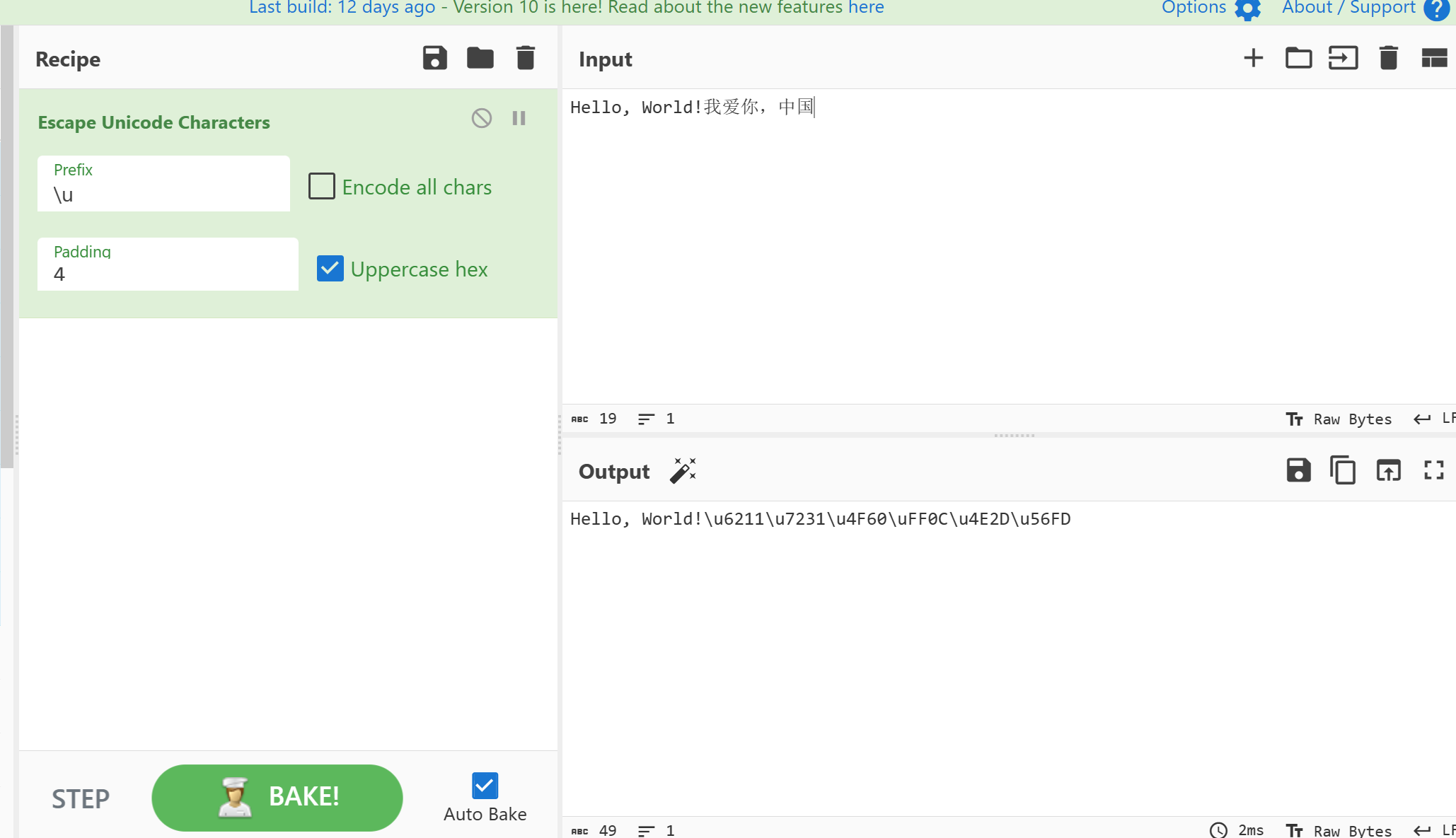
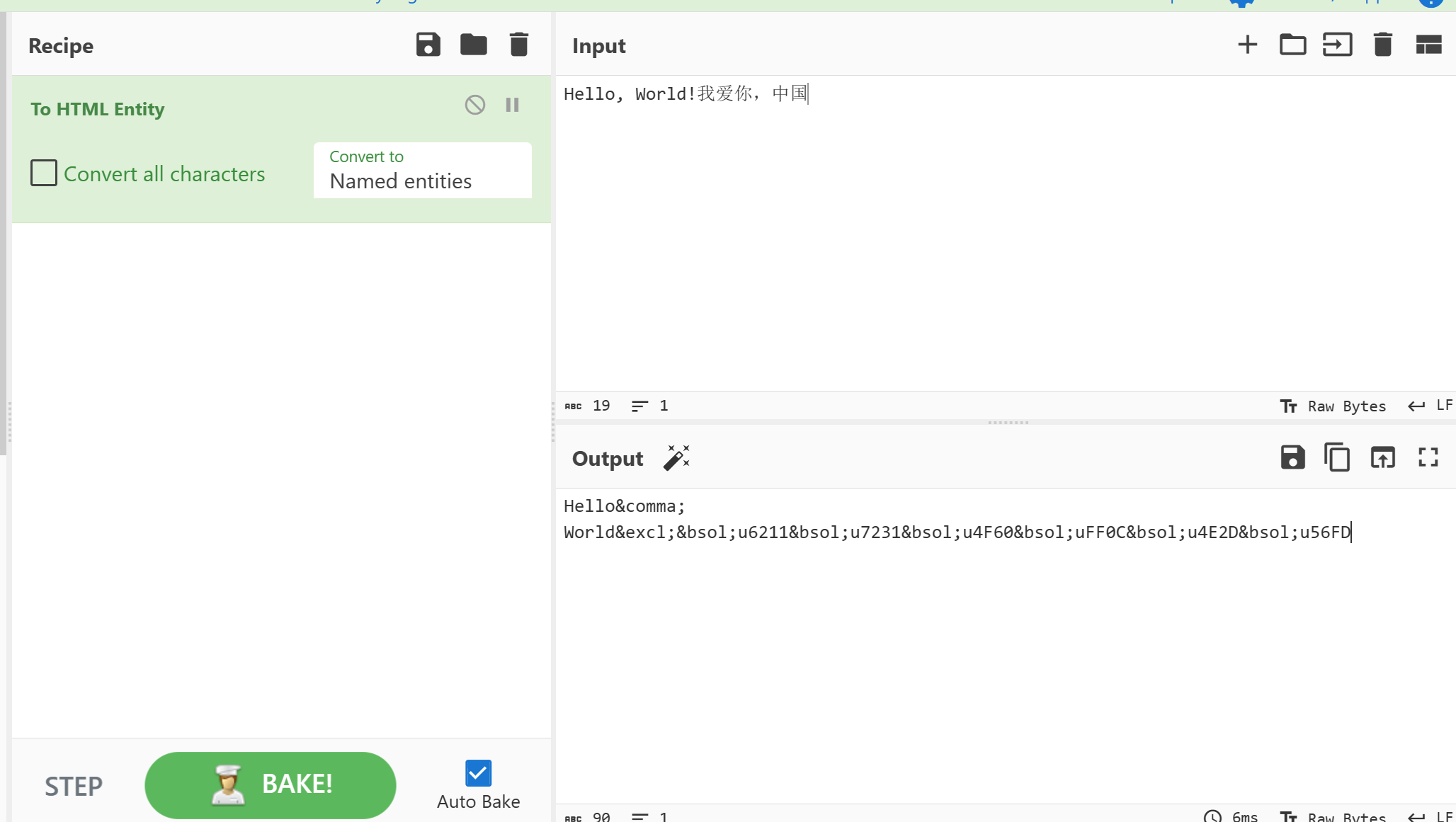
HTML实体编码(HTML Entity Encoding): HTML实体编码用于在HTML文档中表示特殊字符,比如用于显示保留字符(例如小于号和大于号)或不能在HTML文档中直接显示的字符(如版权符号)。
它的形式是
&entity;,其中entity是一个预定义的名称或数字引用,代表特定字符的编码值。
- 特殊字符:小于号 (<)
- HTML实体编码:<
联系和区别:
- URL编码和HTML实体编码都是用于在特定上下文中转义特殊字符,以避免冲突或表示不可见字符。
- Unicode编码是字符的标准化表示形式,用于标识字符在全球范围内的唯一代码点。
识别:
URL编码和HTML实体编码通常以特定的格式出现,如”%xx”和”&entity;”。
Unicode编码通常以U+开头,后跟字符的十六进制码点表示。
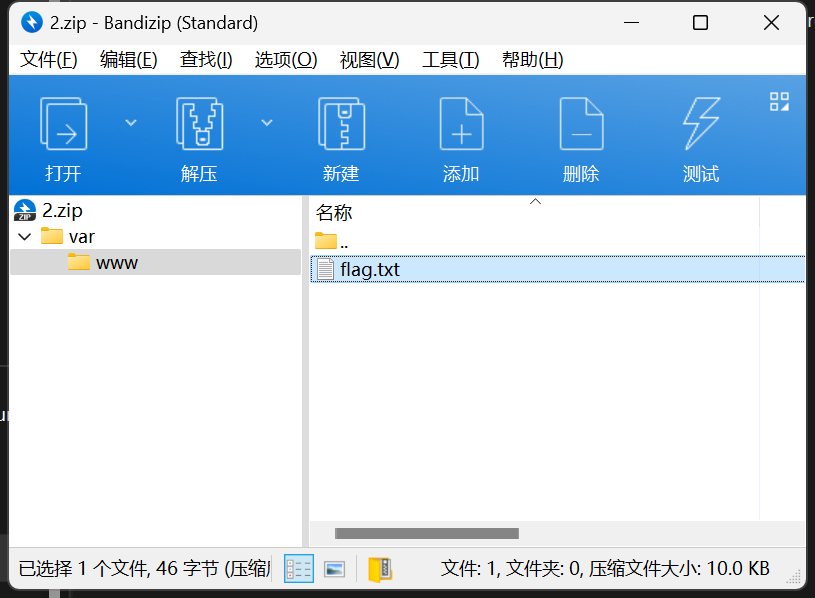
压缩包处理
注:导出文件请转成原始010二进制各式进行导出,防止有不可打印字符没有导出
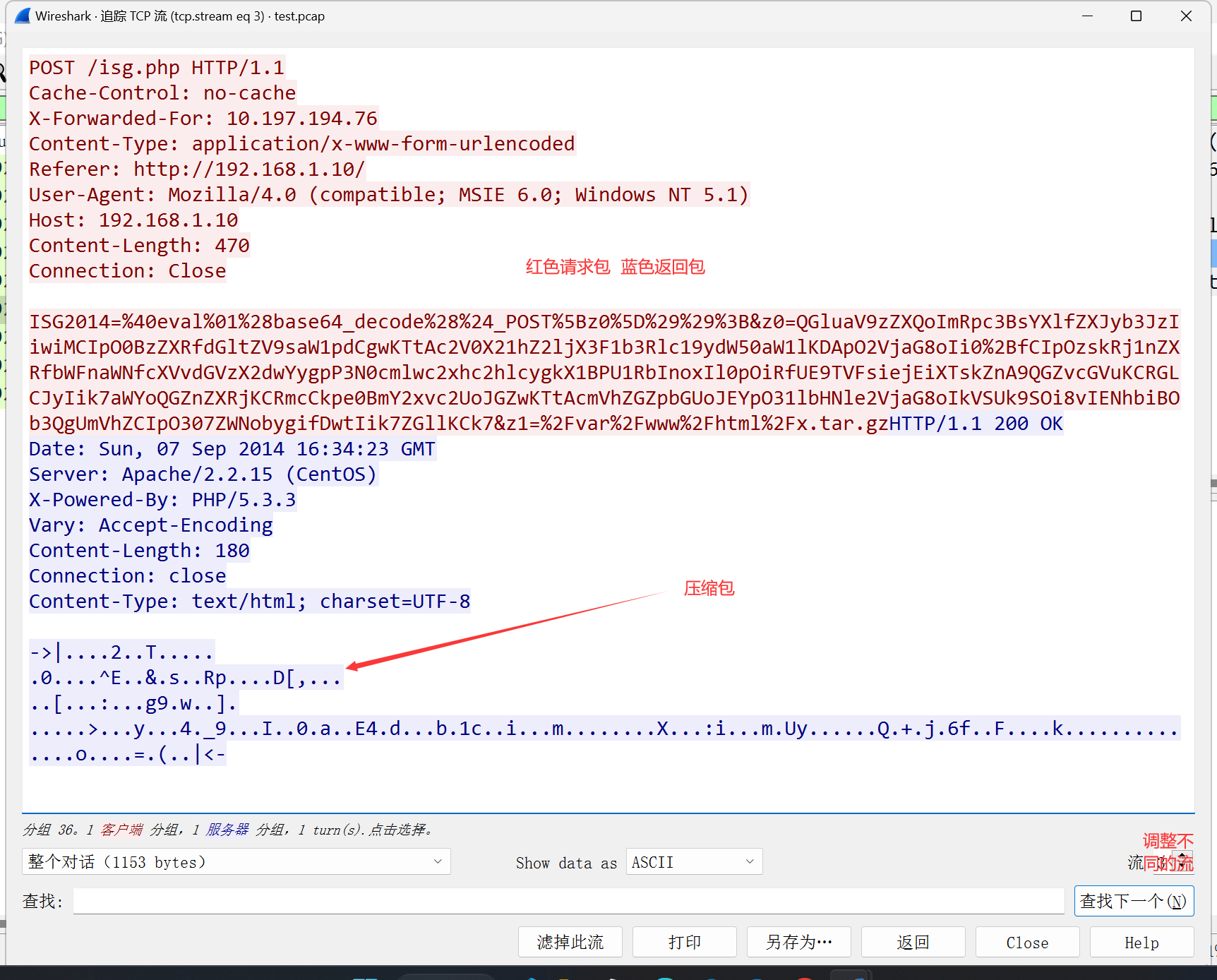
定位到包的位置,选择压缩包格式,用原格式导出即可